
この記事は、『日本の半導体戦略 2024+1/2—NVIDIA と挑む AI チップ企業群』が、2024年11月19日から購入可能になったことを開示するものです。
【本書について】
本書では、日本の半導体製造産業の復活に向けた動向をはじめ、NVIDIAのリーダーであるジェンセン・ファン氏のリーダーシップの本質、そしてNVIDIAに挑むAIチップ企業群の最新動向を詳しく解説します。AI半導体技術革新の波に乗りたいすべての方に向けた必携のガイドブックです。ぜひお手に取ってご覧ください。
【内容の特徴】
世界のAI半導体産業は、かつてない革新の真っただ中にあります。本書は、最新情報と深い分析を織り交ぜ、合計492ページにわたる充実の内容をお届けします。このボリュームは、日本の半導体産業が迎える垂直統合型から水平分業型へのシフトという歴史的な転換期を反映したものです。
【ページ構成】
本書は、最新のAI半導体産業のトピックを以下のように網羅しています:
– 日本の半導体戦略:200ページ (グローバル市場の視点で再評価される日本の製造力とその未来)
– NVIDIAの革新とリーダーシップ:180ページ(NVIDIAのリーダーシップの挑戦と成功の秘訣)
– AIチップ市場の競争:80ページ(次世代AIチップ市場でNVIDIAに挑む新興企業の戦略と可能性)

【店頭販売】
書泉ブックタワーなどの都市圏の主要書店でお求めいただけます。
【一般書店】
学術書専門の取次業者である西村書店(TEL: 03-5879-7681)を通じて、お近くの書店にてお取り寄せが可能です。
【出版社Webストア】
以下のリンクから直接ご購入いただけます。
https://square.link/u/959s727n
【Amazon】
以下のURLよりオンラインでお求めいただけます。
https://www.amazon.co.jp/dp/4911019093
【おすすめポイント】
– 日本の半導体戦略を徹底解説: ラピダスの2nmプロセス挑戦における技術的課題や、世界市場における日本の半導体産業の立ち位置を独自の視点で分析しました。
– AIと半導体の未来を描く: NVIDIAの技術革新と共創モデルがもたらす、21世紀における新たな産業革命のプロセスを探ります。
– 投資家と政策立案者に向けた情報充実: 半導体関連株式の動向や、政府支援策の詳細を取り上げ、意思決定に役立つ情報を提供します。
– キャリア形成のための最新情報: 半導体業界で求められる最新技術やトレンドを網羅し、未来を切り開くヒントを提示します。
【内容】
– 2nmチップ製造の成長可能性と市場動向: 国民が注目する次世代チップ製造技術の課題と展望を深掘り。
– NVIDIAのAIチップとCUDAプラットフォームの進化: 20年にわたる技術革新が支えるNVIDIAの独自エコシステムを詳解。
– ジェンセン・ファン氏のリーダーシップと経営哲学: 半導体業界を牽引するNVIDIA CEOの成功の秘訣を分析。
– 新たなAI市場の競争動向: AMDをはじめ、スタートアップ15社が挑む革新的なAI技術と市場の可能性。
– 国際協力と技術革新の展望: NVIDIAやラピダスを中心としたグローバル連携とその未来像。
– 地政学的リスクへの対応策: 米中対立が半導体業界にもたらす影響と、リスクを乗り越える戦略を解説。
【各章の解説】
● 第 1 章 『日本の半導体戦略とラピダス : 外交 , 安全保障 , 経済政策を統合』
この章では、日本が次世代半導体開発を戦略的に推進する理由を解説。日本の半導体戦略に関する政府の最新発表を網羅的に取り上げています。特に、Rapidusを中心とした日本の半導体製造の「勝算」に焦点を当て、国民が知りたがる情報を可能な限り詳しく収録しました。日本の半導体製造が掲げる「技術飛び越え(leap-frog)」戦略は、成功すれば国際競争力を一気に取り戻す大きなチャンスとなります。2nm技術を手掛ける背景として、競争優位性、新技術(GAAトランジスタ、EUVリソグラフィ、裏面給電など)の導入効果を解説しました。
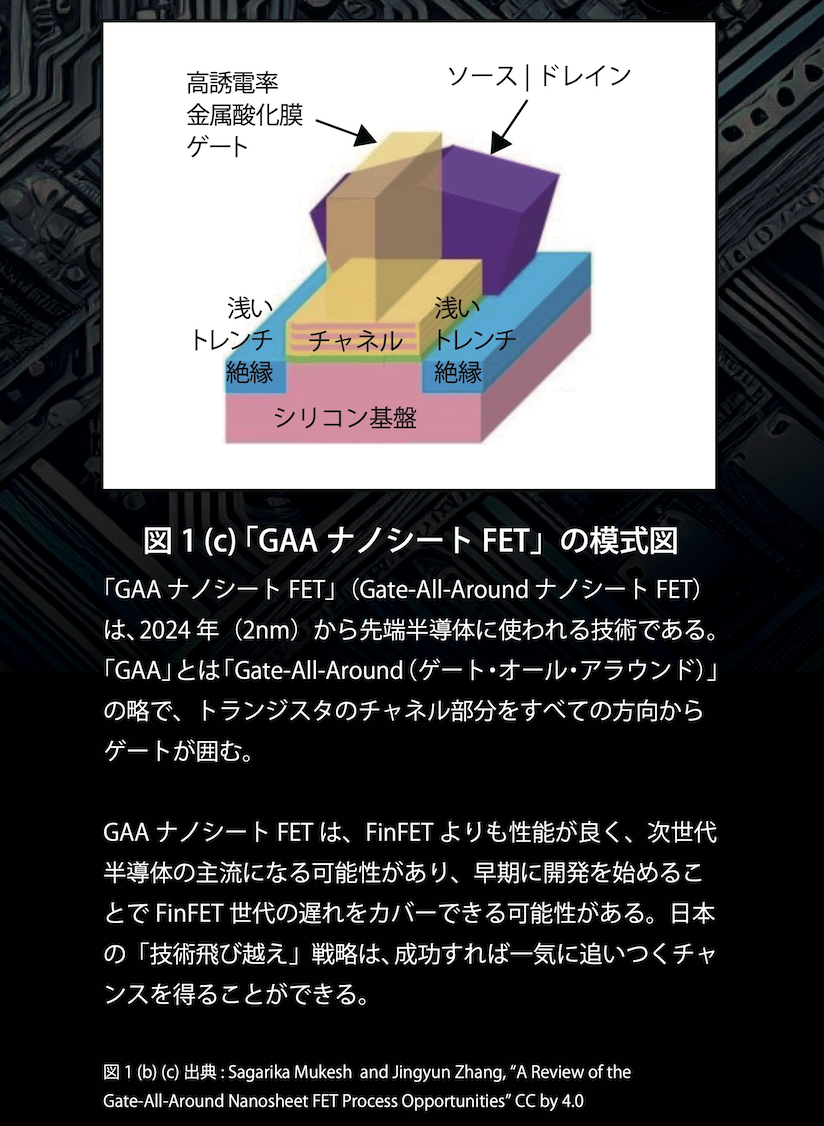
日本の半導体製造戦略は、2nm技術の開発を中心に、競争優位性を確保しつつ、新技術(GAAトランジスタ、EUVリソグラフィ、裏面給電など)の導入による革新を目指しています。この戦略では、半導体産業の歴史やMOSFET技術の進化を踏まえ、次世代技術群(3D積層技術やチップレット設計など)の重要性を強調し、TSMCやSamsung、Intelといった各国の2nmロードマップと比較検討します。ラピダスによる日本独自の2nmファブの進行状況や課題にも触れ、EDAやファウンドリなど、サプライチェーンを構成する主要プレイヤーの役割を整理。さらに、AIコンピューティングや次世代メモリのユースケースを探索し、最先端半導体技術センター(LSTC)を通じた研究開発と人材育成を推進しています。外交・安全保障・経済政策を統合したアプローチで、日本は米中競争の中での戦略的位置づけを強化しつつ、財務的持続可能性や地域経済への波及効果を重視しています。
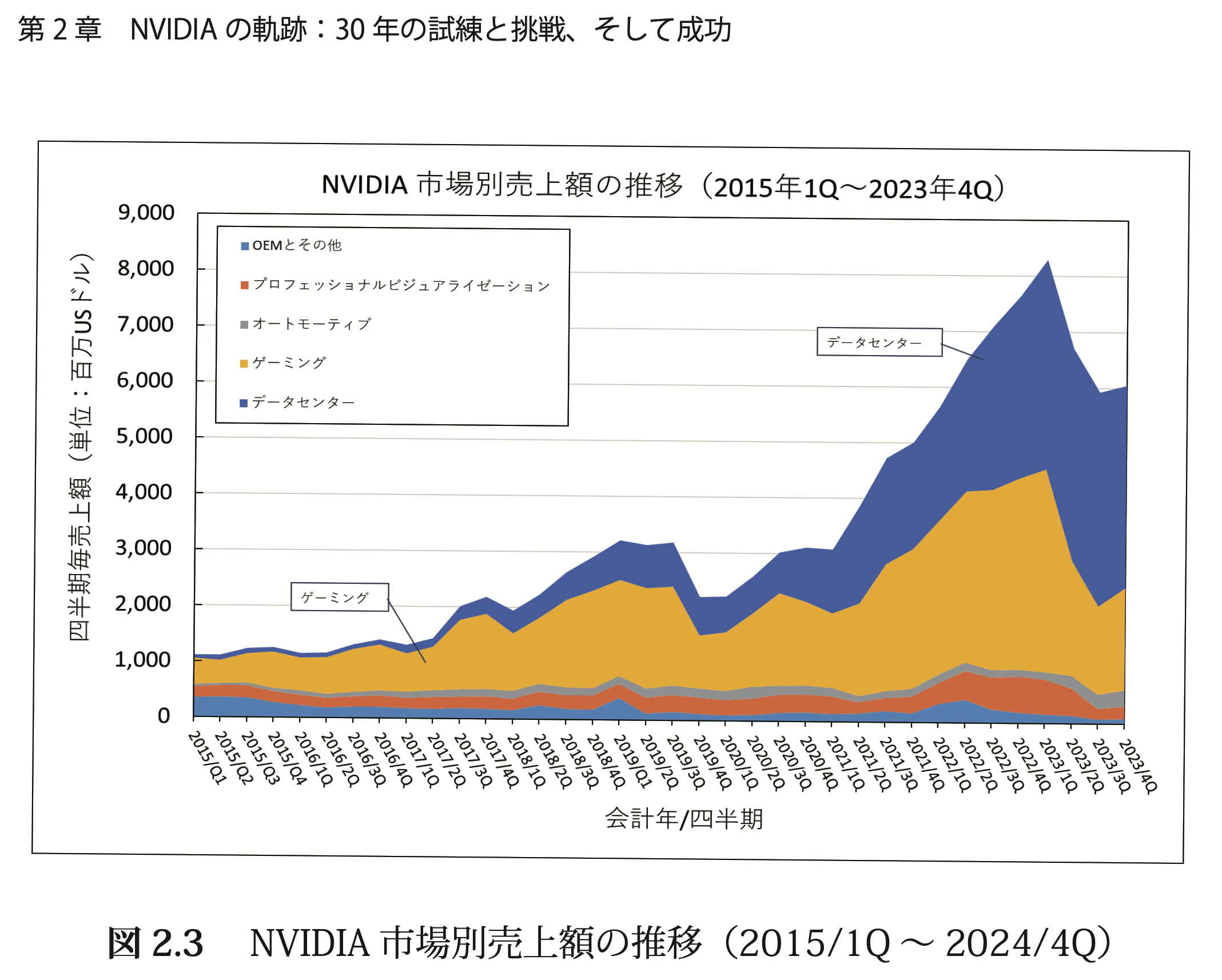
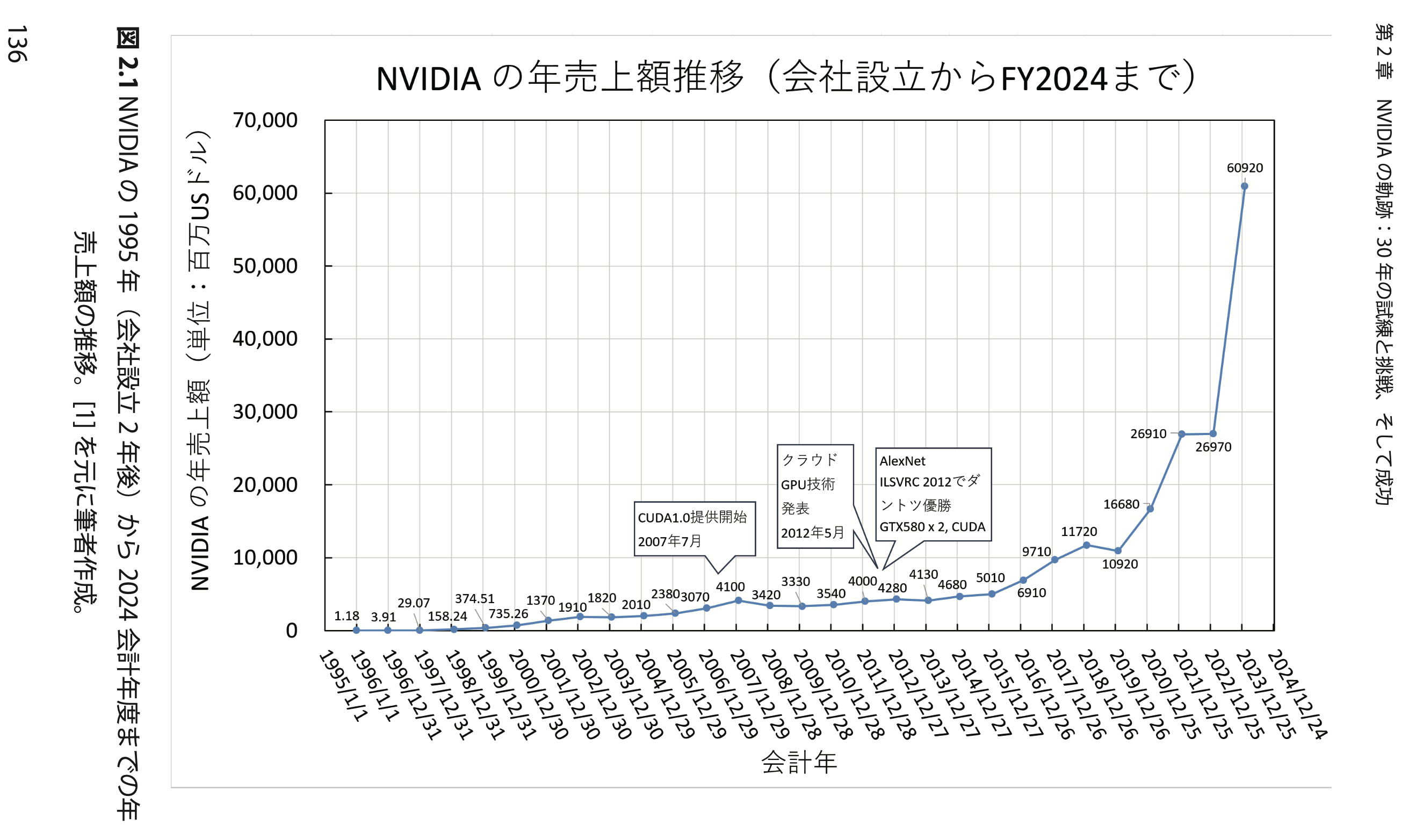
● 第 2 章 『NVIDIA の軌跡:30 年の試練と挑戦、そして成功』
この章では、NVIDIAが創設以来公開した財務資料をもとに、実ビジネスの規模と応用分野などの情報を可視化することで、NVIDIAの実態を分析します。NVIDIAの30年にわたる経営データを、収益成長、GPU市場でのシェア拡大、AIデータセンター向け半導体の進化を中心に、その経営データを集約しています。NVIDIAがデスクトップPC用GPU市場での競争を勝ち抜き、AI向け製品によって収益基盤を強化した際の各年度の応用別売上などをまとめました。NVIDIAの成功を支えた重要なパートナーがTSMC(台湾半導体製造)です。1987年に設立されたTSMCは、ピュアプレイファウンドリモデルを採用し、世界の半導体業界での競争力を築き上げました。NVIDIAはTSMCとの密接な連携を通じて、先進的な半導体技術を実現し、経済的成果を達成することに成功しました。
● 第 3 章 『グラフィックスと AI 革命: ジェンセン・ファンと NVIDIA の挑戦』
この章では、NVIDIAの創設から現在までの30年間にわたる軌跡を、リーダーシップ、製品開発、市場戦略、技術革新、そしてAI革命に至るまで多面的に分析しています。ジェンセン・ファンを理解するために必要となるヒントを提供するため、1994年から2000年、2005年から2006年の頃の、ジェンセンと筆者がじかに接した際のエピソードにもページを割きました。

ジェンセン・フアンは、ジェンセンは、1993 年の創業以来、当初 3D グラフィックス市場に焦点を当て、急成長と停滞の波を繰り返していましたが、2006 年からインテル CPU のワークロード(処理内容)を、少しずつGPU(グラフィックス処理装置)に移すことを目的とした「バラクーダ作戦」をNVIDIAで開始しました。CPUで処理するワークロードを10年以上の歳月をかけてGPUに置き換えることでPC を高性能化し、PC中でのNVIDIA GPU の重要性を増加させる目的でCUDA と呼ばれる汎用GPUソフトウエア開発ツール環境を継続的に開発することを決めました。その後、CUDAによりNVIDIAは、新市場機会 を開拓し続け、ノーベル賞を今年受賞した、ジェフリー・ヒントン(Geoffrey Hinton)の研究開発 が CUDAを使ったため、AI 市場でNVIDIAが大成功し、さらに生成 AI などの分野で NVIDIA の 存在感は増しています。「バラクーダ作戦」および CUDA開発 に端を発した NVIDIA のイノベーションは、業界全体のコンピュータアー キテクチャの方向性に大きな変革をもたすことになります。近年では、NVIDIA は、AI革新により世界最大の企業となり、CEO ジェンセン・フアン(Jensen Huang)は、経済界の頂点に立ちました。
しかし、企業やデータセンター 運営者が「脱 NVIDIA」を目指す動きも見られます。AI チップ市場では、NVIDIAの圧倒的なポジションに挑もうと、AMDやIntelなどの企業や、多くの新興企業が革新的な技術でNVIDIAに挑戦しようとしています。これに対して、NVIDIAは、リーダーシップを維持するため、挑戦する新興企業の社名を自社ウェブに挙げ、これらの挑戦者に対抗すると「宣戦布告」しています。2025年にはこれらのチップが出揃い、 AI チップ市場は「戦国時代」化すると予想されます。

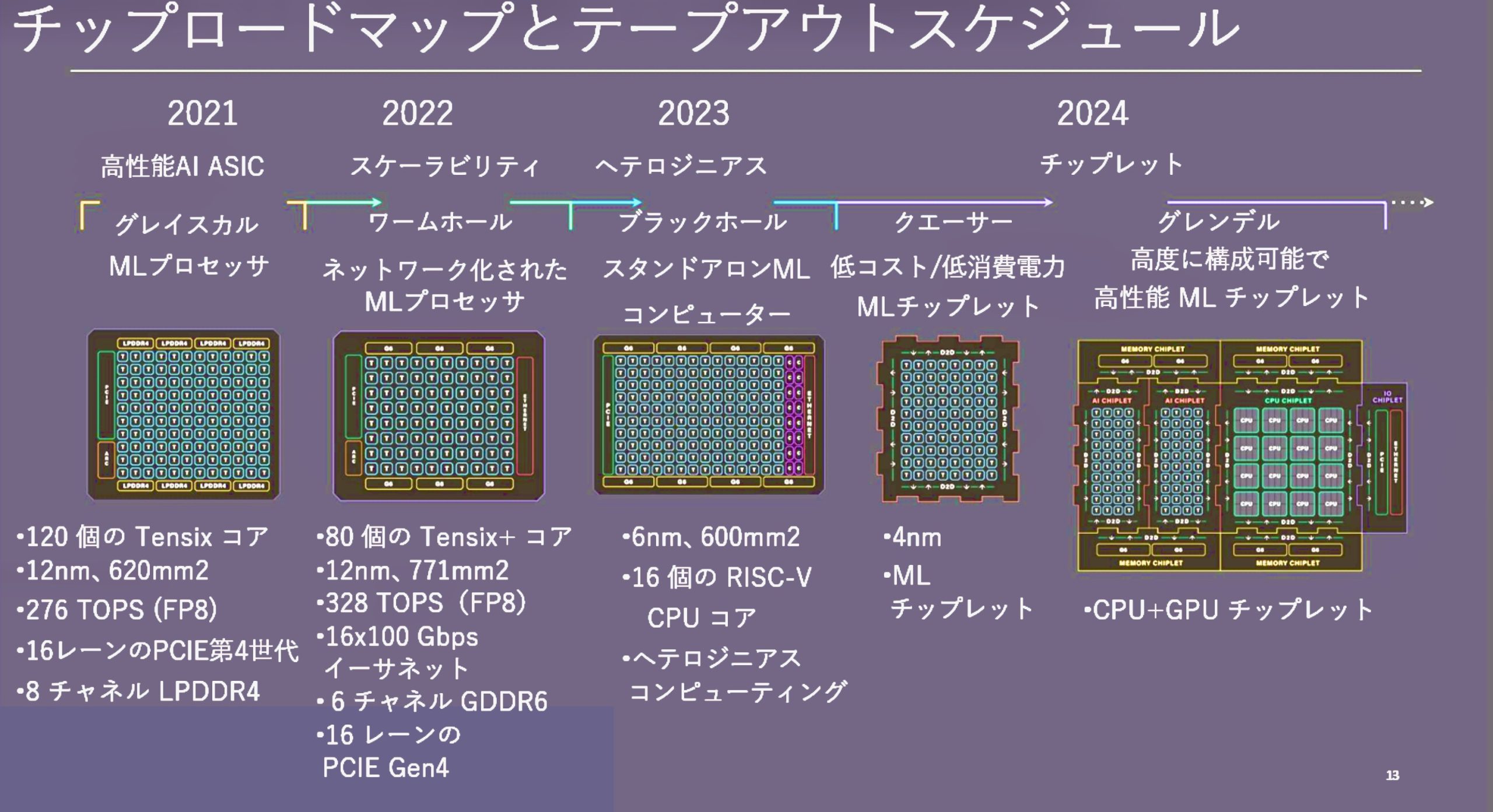
図。NVIDIAに挑むTenstorrent社AIチップロードマップ
● 第 4 章 『Armの新戦略:TSMC 最適化 IP で性能・効率・面積を改善』
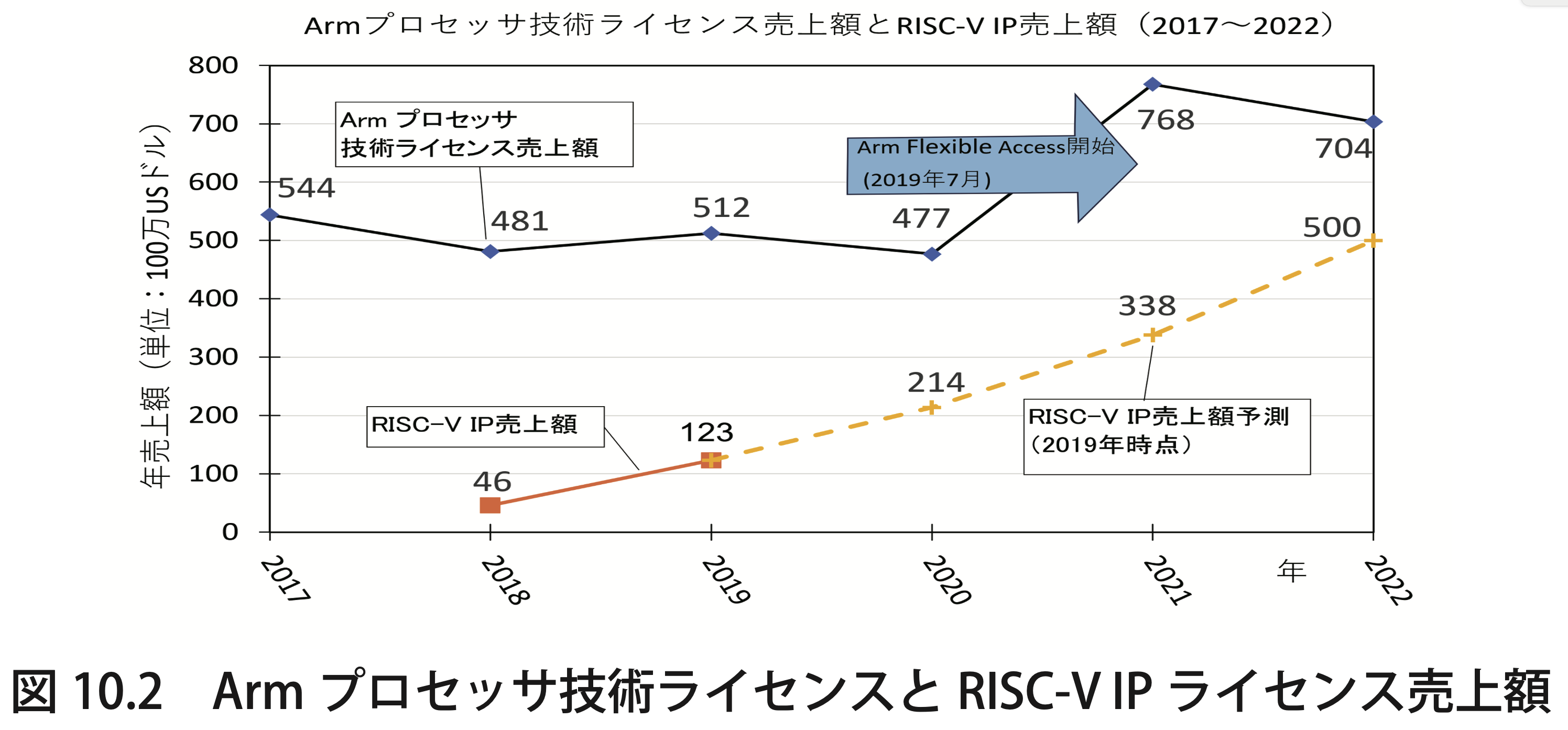
近年、Armは「TSMCで製造するために最適化された半導体IP(Intellectual Property: 知的財産)」を提供することで、半導体チップの性能、効率、および面積 (PPA:Performance, Power, Area)の改善を図る新戦略を打ち出しています。この戦略は、特に、台湾のTSMC社における最先端プロセス(5nm、3nm など)に適合するように設計しており、ユーザ企業にとって競争力のあるチップ設計が可能になるようサポートしています。半導体技術が進歩するにつれ、各プロセスノードの開発コストが高騰し、製造プロセスと IP の緊密な最適化が求められます。 TSMC社は 5nm や 3nmといった先端プロセスで他のファウンドリをリードしており、これに合わせた最適化 IP を提供することは、Arm にとって大きな競争優位となります。ArmのTSMC 最適化 IP 戦略は、現在の 市場ニーズに応えるための戦略です。

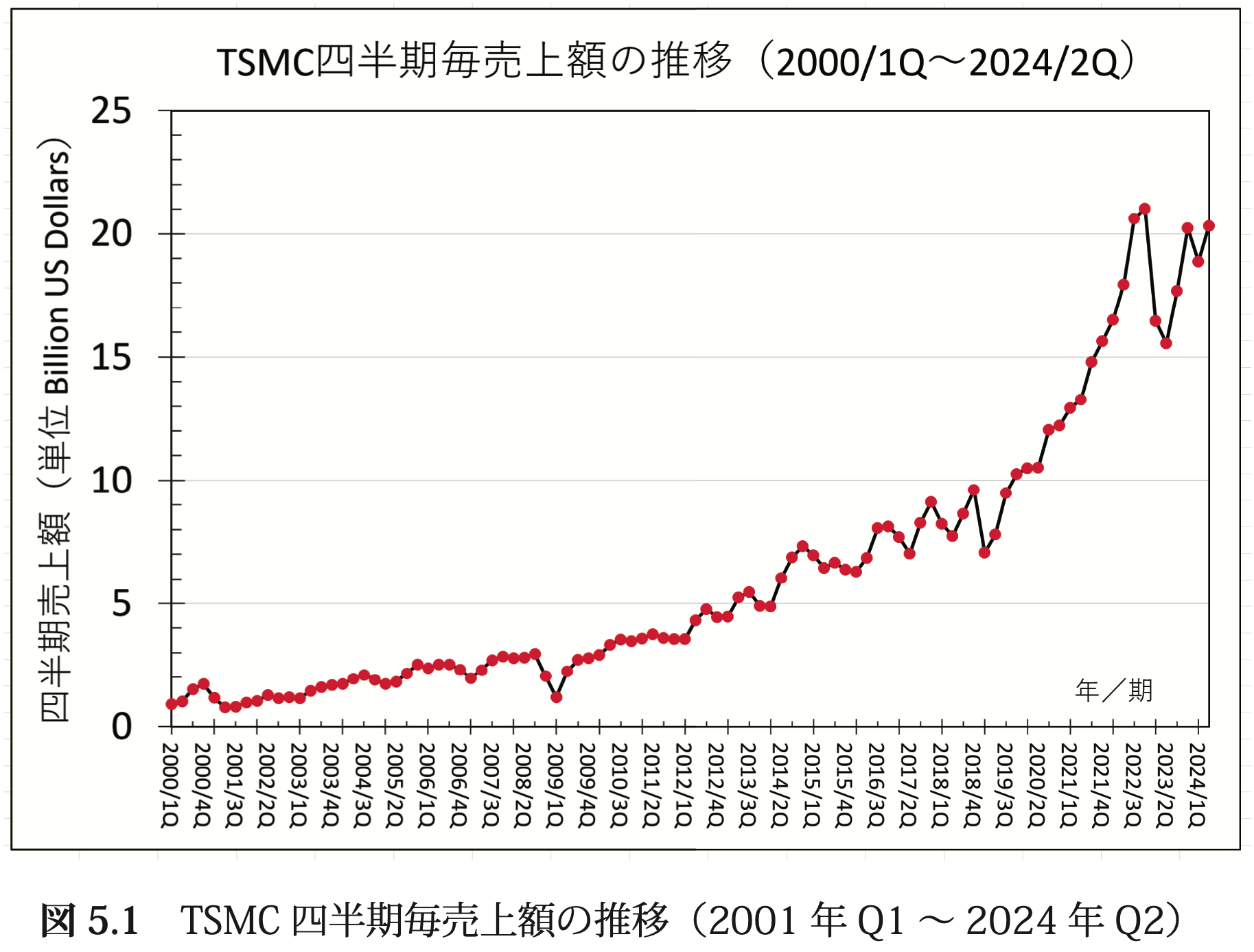
● 第 5 章 『TSMC の 24 年間:売上推移と技術ノードの変遷』
2024 年現在の時点では、ファブレス半導体モデルが垂直統合型半導体モデル(IDM) に勝利したと言えます。インテルが 10nm プロセスノードで TSMC に敗北し、TSMC が最先端技術を先行したからです。インテル 10nm プロセスノードは遅延が続き、 その間に TSMC が 7nm および 5nm プロセス技術を商業化し、先端半導体市場での優位性を確立しました。Apple が 2020 年に Mac の チップ調達をインテルからの購入から自社設計 +TSMC 製造委託に切り替えた時、インテルの技術的優位性が大きく揺らぎました。この劇的な変化により、ファブレス半導体メーカー(TSMC が製造を担当)と垂直統合型半導体メーカー(IDM)間の力関係が大きく揺れ動き、TSMC社が世界のビジネスリーダーとなりました。
2024年12月までインテルのCEOを務めていたパット・ゲルシンガー(Patrick Paul Gelsinger)は、自社の垂直統合型半導体企業、つまりIDM(Integrated Device Manufacturer)モデルを維持しながら、専業ファウンドリ事業への進出を目指した改革を推進しました。インテルは「IDM 2.0」という戦略を掲げ、自社製品の設計・製造を担う部門と、外部顧客向けにファウンドリサービスを提供する部門の両立を目指しています。
一方で、TSMCはNVIDIAなどの主要企業を顧客とすることで、モバイルからAIデータセンターへと技術リーダーの中心が移行する中で、急成長を続けています。特に2nmプロセスへの移行は、半導体市場に大きな変化をもたらすと予想されており、TSMCの役割は今後も高い重要性を維持すると考えられます。これに伴い、技術革新や競争環境の変化について、引き続き注目が必要です。

● 第 6 章 DARPA 自動設計フローと Google 支援シャトルで RISC-V 開発
DARPA(アメリカ国防高等研究計画局)では、2018 年から、半導体設計を自動化するためのオープンソースツール群「オープンロード」を開発しています。
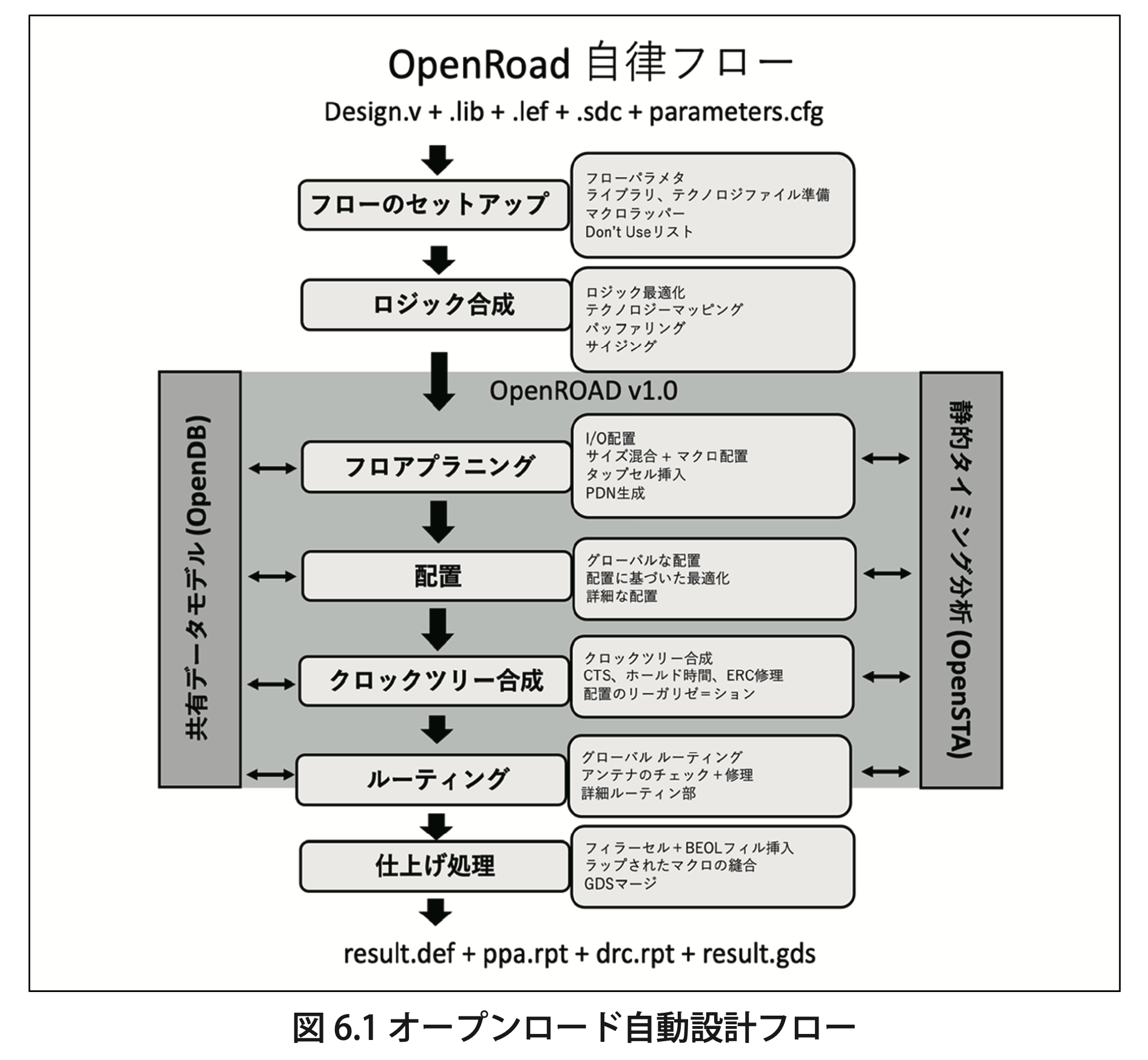
2022 年にGoogle無償シャトルを使わせていただき、NEDO委託事業の一環として「オープンロード」ツール群を使い RISC-V や SH-2など小規模な SoC チップを 3 回テープアウトしました。2023年末、忘れかけた頃に、 SkyWaterファブで製造された3 つのシャトル試作品が、eFabless 社から到着しました。2024 年 3 月から、一般社団法人組込システム技術協会(JASA)の協力も得て、1 つ目の MPW-6(RISC-V)試作品を評価することができました。25MHz(メガヘルツ)で正常動作し、「オープンロード」が現実に役に立つことを体感しました。設計フロー の信頼性が確認され、外付けフラッシュメモリや PSRAM 高速インタフェース IP 機能を評価中です。




● 第 7 章 RISC-V と共に成長するアンデス:台湾 No.1 IP 企業の未来
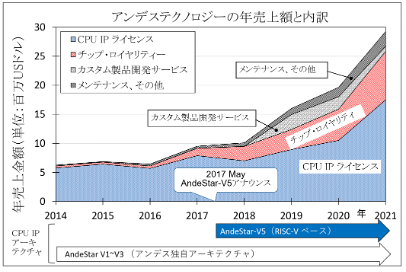
アンデス・テクノロジー(Andes Technology)は、2020 年 12 月から 台湾証券取引所(TWSE)で、株式コード「6533」で取引されている上 場企業です。過去数年の年平均成長率は約 52% であり、2030年代初頭にArm に追いつき、追い越す可能性がある台湾のナンバー 1 半導体 IP プロバイダーです。1980 年代から、ファブレス半導体モデルを定義したArm のライセンスモデルは長らく業界標準とされています。
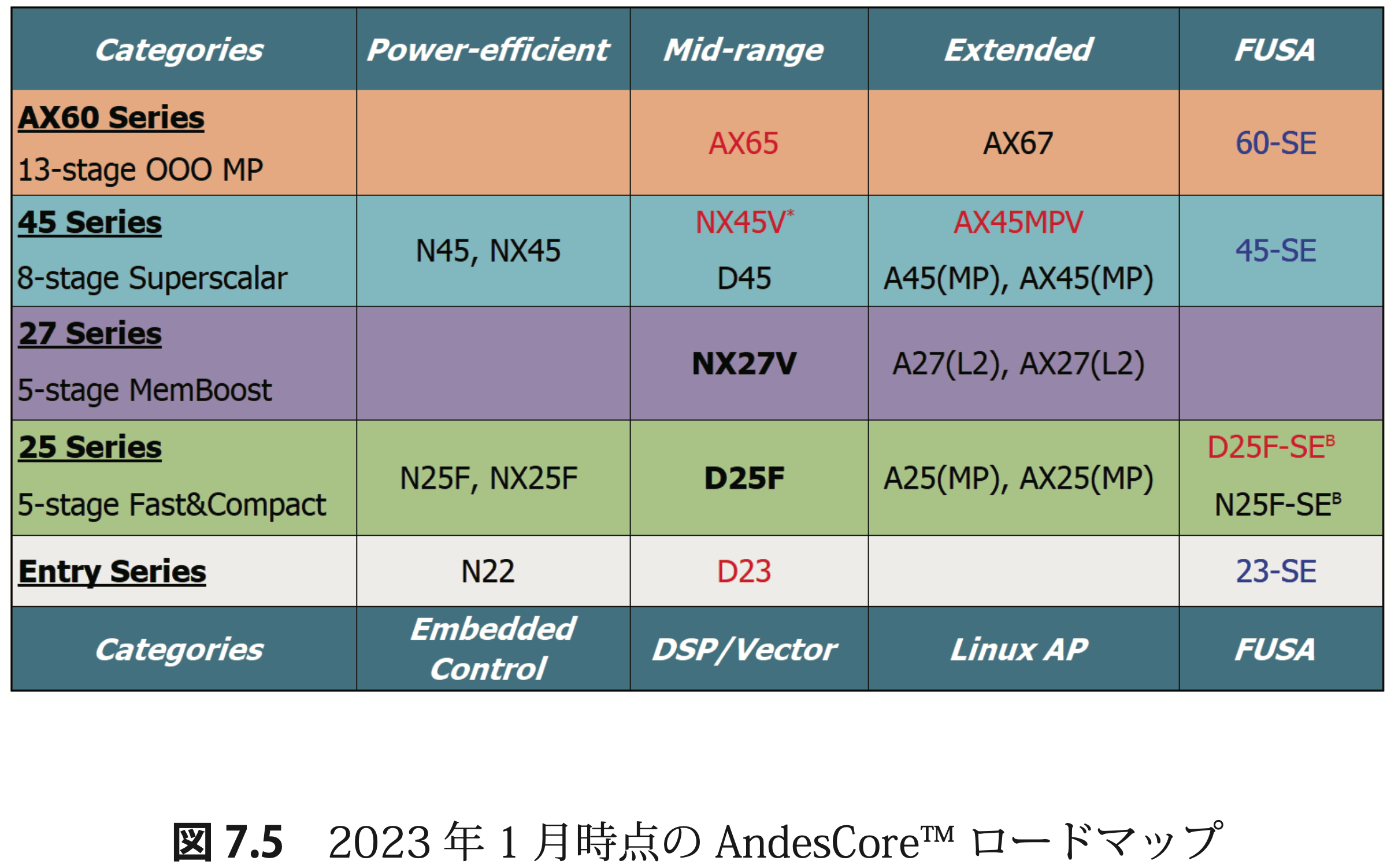
2005 年の設立当時からアンデス・テクノロジーは、柔軟なライセンスモデルを市場に導入し、ローエンドの CPU IP で ARM のローエンド CPU IP に挑戦し、日本国内の大手テレコム機器、モバイル基地局用機器、放送機器、半導体製造装置などの企業が、相次いでアンデスの CPU IP を採用しました。Armは、対抗措置として自らもフレキシブルライセンスを 導入しましたが、Arm従来の固定ライセンスモデルよりも収益性が低いため、 Armの収益構造に大きな影響を与えました。アンデス・テクノロジーは、2016 年からオープンアーキテクチャであ る RISC-V を採用し、これが現在の成長戦略を支えています。
● 第8章 テンストレントが提供する DX のためのスケーラブルな RISC-V
Tenstorrent は、NVIDIA に挑戦すると宣言する企業のうちの1社です。 2024年1月16 日に訪日した際のプレゼンテーションを口述筆記し 日本語に翻訳しました。Tenstorrent は、「Grandale」と呼ばれるヘテロジニア・コンピューティングプラットフォーム製品を市場に紹介し、2025 年 に NVIDIA の「Grace Hopper」に正面から挑む予定です。
● 第 9 章 マイクロコントローラからマルチコア SoC RISC-V ベースの チップのデバッグが簡単に
自動車、社会インフラ、医療機器などに搭載するソフトウエアの機能 安全を高めるために使われるローターバッハが開発した高級デバッグ用エ ミュレータツールです。設計プロセス中に問題を作り込むことを未然に防ぐことで、最終製品の安全性と信頼性を高めます。自動車、社会インフラ、医療 機器応用では、機能安全に対応するため高度なデバッグ環境が必要です。
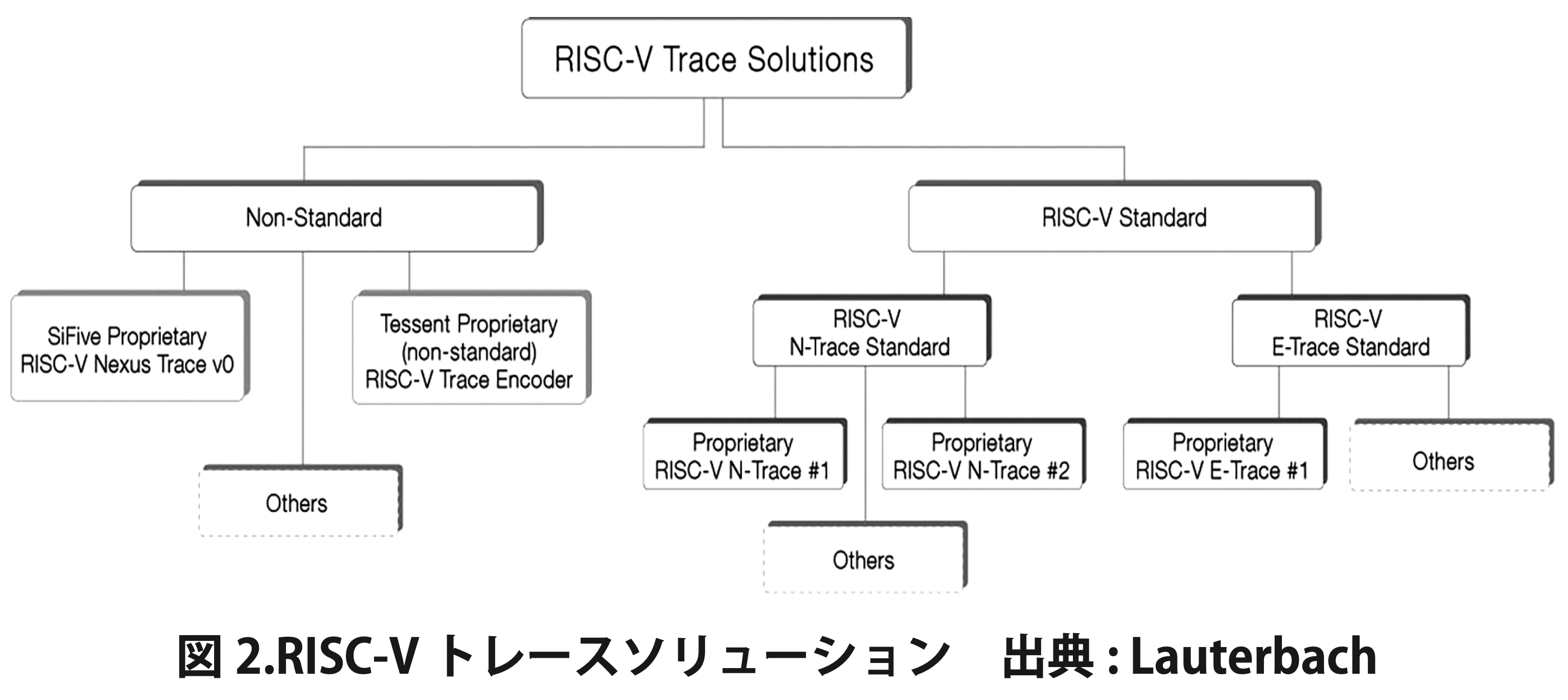
● 第 10 章 RISC-V と米中対立 : 分断を超えて続くオープンソース協力
RISC-Vはオープンな工業規格であり、同盟国や非同盟国を問わず、世界中の企業や研究機関が同一の規格に基づいてプロセッサや関連技術の開発を進めている点が特徴です。ロシアや中国を含む多くの国が、RISC-Vを独自に開発・利用しています。
2023年には、米国の一部議員がRISC-V技術への輸出規制を検討しましたが、RISC-Vはオープン規格であり、特定の技術や実装に限定されないため、規制は困難とされ、最終的に規制には至りませんでした。RISC-Vの共通仕様に基づく基本設計は、米中両国が開発した技術にも互換性を持たせています。ただし、輸出規制や米中対立の影響により、応用ソフトウェアやハードウェアの開発における両国間の協力は減少していますが、基本技術(メインライン)仕様に関する協力は現在も続いています。
[解説]
ラピダスの2nm製造に向けた挑戦は、日本の半導体産業が再興を目指すための象徴的な取り組みです。本書は、NVIDIAやAMDといった競争相手、そして日本の産業界の努力を背景に2nm時代を切り開く鍵となる要素を解説します。AI時代を背景に、日本がどのようにして半導体のグローバル競争に立ち向かい、NVIDIAやAMDと連携・競争しながら技術的リーダーシップを確立しようとしているかを、多角的な視点から描きます。日本の2nm半導体戦略、その挑戦と未来。ラピダスをはじめとする日本企業が直面する微細加工技術を使った半導体製造の課題と解決策を紹介します。
課題1: 技術力の確立
GAA(Gate-All-Around)トランジスタ、裏面給電(BSPD)、と良品率(歩留)
課題2: グローバル半導体サプライチェーンの一翼を担う
垂直統合型でなく水平分業の水平分業型へ
課題3: 半導体人材育成と資金調達
先端製造技術を支える人材不足と長期的な資金計画
課題4: グローバル競争
先行するTSMCやサムスンとどう競うか。課題5: 技術革新を支える政策と資金調達の仕組み
石破首相が表明した、AI半導体の支援政策について成否を分ける要因を分析します。
[タイトル・基本情報]
『日本の半導体戦略 2024+1/2 NVIDIA と挑む AI チップ企業群』
単行本: 492 ページ (147 × 209 ミリ)
価格: 2000 円(外税)
編集: 田胡 治之 監修: 田邊いづみ 装丁: 中嶋敬之
発売日:2024 年 11 月 1 日 第一版第 1 刷 発行
販売先:主要書店、通販サイト、自社サイト(https://sohacoinc.square.site/)から
詳しくは、自然科学書専門卸 株式会社西村書店にお問い合わせください。
発行者 : 河崎 俊平
発行 : 株式会社ソハコ 出版局
推薦 : 一般社団法人 RISC-V 協会
東京都中央区銀座 7 丁目 18 番 13-502 号
電話 03-5565-0556 代表 03-3833-3717
メール sohaco@swhwc.com
書籍コード: ISBN 978-4-91109-09-2
分野コード: C0034
定価: 本体 2000円+税
発行: ソハコ 出版局
テクノロジーB2-53 ハードウエア 開発
コンピュータ アーキテクチャB8-02
深層学習 ディープ ラーニング
[目次]
• まえがき vii
1. 日本の半導体戦略とラピダス : 外交、安全保障、経済 政策を統合 1
1.1 なぜ 2nm ファブが必要なのか? 1
1.1.1 新技術導入による競争リセット効果 1
1.1.2 GAA トランジスタ技術の導入 2
1.1.3 EUV(極端紫外線)リソグラフィ技術 3
1.1.4 裏面給電(BSPD)技術 3
1.1.5 新しいパートナーシップと製造設備へのアクセス 3
1.1.6 大手企業と新規参入企業に共通の学習曲線 4
1.1.7 パラダイムシフトのタイミングに乗る 4
1.2 MOSFET(金属 – 酸化膜 – 半導体)の 65 年史 4
1.2.1 日本勢はプレーナー MOSFET で開発競争から撤退 6
1.2.2 FinFET の展開はグローバルに 8
1.2.3 FinFET は日本の技術者の着想から発展した 9
1.2.4 FinFET を追いかけた日本の技術者たち(2014) 10
1.2.5 2nm で GAA(Gate-All-Around)に移行(2024) 11
1.2.6 FinFET から GAA は変革ではなく進化? 12
1.3 2nm プロセスに付随する「次世代技術群」 15
1.3.1 裏面給電(BSPD)で性能と面積を改善 16
1.3.2 シリコン貫通配線(TSV=Through-Silicon Via) 17
1.3.3 2nm で既に裏面給電を完成したインテル 18
1.3.4 インテルは裏面給電ウエハ製造工法も開示 19
1.3.5 裏面給電はコストアップしないとインテルは予想 20
1.3.6 2nm 表面給電(FSPD)は EUV 使用回数が増加 20
1.3.7 インテル曰く裏面給電で歩留まりは劣化しない 21
1.3.8 シリコン貫通垂直電気接続が 3D 積層技術に必要 21
1.3.9 インターポーザが 2.5D 積層技術には必須 22
1.3.10 インテル、AMD は独自チップレットを開拓 22
1.3.11 インテルの独自チップレット技術「Foveros」 23
1.3.12 AMD もチップレット技術を独自に開拓 25
1.3.13 NVIDIA におけるチップレット技術 28
1.3.14 チップレットの相互運用性と標準化 30
1.3.15 UCIe(Universal Chiplet Interconnect Express) 31
1.3.16 AIB: Advanced Interface Bus (2018) 32
1.3.17 Die-to-Die(D2D)規格を支配する 10 社 33
1.3.18 チップレットを売るビジネス 35
1.3.19 アルファウェーブセミのチップレット事業 36
1.3.20 3D および 2.5D 積層技術と裏面給電 36
1.3.21 先端ノードでの極端紫外線リソグラフィ(EUV) 37
1.4 TSMC における 2nm 以降のノードの状況 40
1.4.1 TSMC の EUV 導入状況 40
1.4.2 TSMC の 2nm 以降のロードマップ: 41
1.5 Samsung 2nm ロードマップ 43
1.6 Intel の 2nm ロードマップ 45
1.7 ラピダスの 2nm ファブ 47
1.7.1 次世代半導体ファブを日本が持つ意義 47
1.7.2 ラピダスの 2nm 日程 48
1.7.3 ラピダス 2nm 日程は遅いのか? 48
1.8 半導体サプライチェーンを構成する 8 つの主要業態 50
1.8.1 EDA(Electronic Design Automation)企業? 50
1.8.2 IP(Intellectual Property)プロバイダー 50
1.8.3 ファブレス(Fabless)半導体企業 51
1.8.4 半導体製造会社(ファウンドリ) 51
1.8.5 IDM(Integrated Device Manufacturer) 51
1.8.6 OSAT(Outsourced Semiconductor Assembly and Test)52
1.8.7 半導体材料供給企業(Materials Suppliers)企業 53
1.8.8 半導体製造装置メーカー 53
1.9 日本の半導体戦略の概観 54
1.9.1 半導体製造基盤の強化 54
1.9.2 地域経済を刺激する半導体関連企業進出と雇用創出: 54
1.9.3 半導体復興の定量目標(2030 年に 15 兆円売上達成) 55
1.9.4 半導体関連の補正予算額 56
1.9.5 新法施行と巨額投資:国内半導体ファブ強化策 57
1.9.6 国内半導体産業の生産促進税制の新設 60
1.10 グローバルな半導体競争 61
1.10.1 主要国の取り組み 61
1.10.2 次世代半導体確保 62
1.10.3 次世代ロジック・メモリ半導体製造の取り組み 62
1.10.4 最先端半導体製造エコシステムの確立 63
1.10.5 ラピダス株式会社 66
1.10.6 ラピダス社への追加支援 67
1.10.7 ラピダスの今後の事業フェーズと支援 69
1.10.8 Beyond 2nm 世代に向けた半導体技術 70
1.10.9 世界に先駆け先端半導体へ投資支援を開始 72
1.11 次世代半導体ユースケースの開拓 73
1.11.1 AIやコンピューティングにおける役務の階層構造 73
1.11.2 メモリ・ストレージ戦略 74
1.11.3 AI計算用メモリの方向性 75
1.11.4 次世代半導体実現に向けた最近の取り組み 77
1.11.5 ラピダス西海岸拠点(Rapidus Design Solutions) 78
1.11.6 Tenstorrent社とEsperanto社との連携 79
1.11.7 なぜ次世代半導体にチップレットが必要か? 80
1.11.8 先端パッケージ戦略の重要性と取り組み 82
1.11.9 先端半導体後工程の先端パッケージ技術の開発 83
1.12 最先端半導体技術センター(LSTC) 85
1.12.1 最先端半導体技術センター(LSTC)の組織 85
1.12.2 LSTCの研究開発プロジェクト 86
1.13 先端半導体が外交にもたらす利点 88
1.13.1 レガシー半導体の産業支援と経済安全保障 88
1.13.2 米国のレガシー半導体に関する調査 88
1.13.3 半導体関連産業におけるセキュリティの確保 89
1.13.4 技術・データの流出リスクと対策 90
1.13.5 半導体国際協力 91
1.13.6 日米首脳会談および日米比首脳会合 93
1.13.7 第3回日米商務・産業パートナー(JUCIP)会合 94
1.13.8 日EU間の半導体協力 95 1.13.9 日英間の半導体協力 96
1.13.10 日蘭間の半導体協力 97
1.13.11 米国と EU における研究開発支援体制の概要 98
1.14 日本の半導体戦略の財務的なサステイナビリティ 100
1.14.1 財政制度分科会(令和6年4月9日開催)の内容 100
1.14.2 各国半導体支援策の規模(税制と最新状況を反映) 101
1.15 世界各国の半導体戦略 102
1.15.1 米国における半導体支援プロジェクト 102
1.15.2 TSMC海外投資と政府支援:各国比較 104
1.16 電力需要と半導体 106
1.16.1 データセンター電力需要 106
1.16.2 AI データセンター(DC)誘致とエネルギー対策 107
1.16.3 一般送配電事業者の AI データセンター取り組み 110
1.16.4 GX グリーン・トランスフォーメーション実行会議 111
1.16.5 AI・データセンターを支えるエネルギー供給 112
1.16.6 AI データセンターと計算資源の高度化 113
1.16.7 AI 計算基盤の最適化と消費電力の管理 115
1.17 半導体人材育成 118
1.17.1 先端半導体開発・人材育成拠点の整備 118
1.17.2 LSTCの活動による研究開発と人材育成の強化 119
1.17.3 海外機関との連携と人材育成 120
1.17.4 半導体人材育成に関する取り組み 121
1.17.5 東北地域における半導体人材育成の取り組み 122
1.17.6 高度人材育成の重要性と具体的取り組み 122
1.17.7 半導体材料のサプライチェーン強化 123
1.17.8 LSTCの人材育成ワーキンググループ(WG) 124
1.17.9 半導体人材育成を推進する地域コンソーシアム 126
1.18 地域社会への経済波及効果 127
1.18.1 熊本県への経済波及効果 127
1.18.2 熊本県への半導体関連企業の進出と投資 128
1.18.3 岸田総理・TSMC・地場企業円卓会議 129
1.18.4 経済安保基金で半導体サプライチェーン強靭化支援 130
1.19 出典 134
2. NVIDIA の軌跡:30 年の試練と挑戦、そして成功 135
2.1 NVIDIA 売上高の推移 135
2.2 デスクトップ PC 用 GPU カードの各社シェア 139
2.3 NVIDIA データセンター向け AI 半導体 140
2.4 参考文献 141
2.5 NVIDIA と台湾半導体製造の連携:協力で築いた成功 143
2.5.1 1960 年代 後工程から始まった挑戦と変革 143
2.5.2 1970 年代 前工程技術導入と応用主体の経営戦略 144
2.5.3 1980 年代 半導体業界を変えたピュアプレイ ファンドリ 148
2.5.4 TSMC の成長 151
2.5.5 台湾の半導体製造産業とエヌビディア 153
2.5.6 参考文献 154
3. グラフィックスと AI 革命:ジェンセン・ファンと NVIDIA の挑戦 155
3.1 NVIDIA とジェンセン・ファン 155
3.2 NVIDIA 創立 156
3.2.1 NVIDIA 設立 (1993 年 ) 156
3.2.2 ジェンセン ファン「黃仁勳」(Huáng Rénxūn) 156
3.2.3 共同創設者たち 159
3.3 NVIDIA の黎明期(1993) 168
3.3.1 NVIDIA の名前の由来 168
3.3.2 NVIDIA 設立当時の 3D グラフィックス技術 171
3.4 最初の製品 NV1 175
3.4.1 STMicro と製造提携(1995) 175
3.4.2 マイクロソフト DirectX(1995) 180
3.4.3 セガ向け NV2(1995) 180
3.4.4 静かなる方向転換(ピボット)(1996) 181
3.4.5 従業員の 50% をカット 182
3.4.6 食堂を閉鎖したが毎晩のピザ注文は続行 186
3.4.7 NV1 返品を山積みしモニュメントを作る 187
3.4.8 NVIDIA をステルスに戻し再出発 189
3.4.9 セガ社内次世代コンソール開発コンテスト(1996) 191
3.4.10 セガオブアメリカ 11 人がを日立に移籍(1996) 194
3.4.11 3dFx のその後(1996) 194
3.4.12「ブラックベルト」vs「.刀」の余波(1996) 195
3.4.13 『バブル経済』(1992)と『独立企業原則』(1994) 196
3.4.14 ナプキンに書かれた700万ドルのMOU(1996) 197
3.4.15 セガとのNV2開発契約を円満解消(1997) 199
3.4.16 ドリームキャストはImaginationへ(1997) 200
3.4.17 DRAMの市場急変で日立半導体も経営難に(1996) 201
3.5 3D アクセラレータから GPU へ(NV3-NV20) 201
3.5.1 Microsoft が DirectX を推進(1995 年 9 月) 201
3.5.2 NVIDIA から見た TSMC(1996) 205
3.5.3 NV3: RIVA 128 でシェア 10~15% 獲得(1997) 207
3.5.4 NV10: GeForce 256(1999)を GPU と命名 209
3.5.5 GPU ドライバソースは非公開(1999) 213
3.5.6 プログラム可能な GPU: NV20: GeForce 3(2001) 214
3.6 NVIDIA における OS 開発 217
3.6.1 NVIDIA の OS 開発チームの規模 218
3.6.2 NVIDIA が OS 開発に熱心な訳 218
3.6.3 ブルースクリーンの 99% は NVIDIA ドライバ起因? 221
3.6.4 2000 年のグラフィックスベンチマーク事情 223
3.7 NVIDIA の財務 223
3.7.1 NVIDIA の IPO 時のジェンセンの持ち株比率 224
3.7.2 無借金経営 224 3.7.3 NVIDIA の筆頭株主たち 225
3.8 2000 年代:多様化と市場支配 226
3.8.1 新しい市場への拡大 : データ センター、自動車など 226
3.8.2 主要な新製品世代の発売と技術の進歩 231
3.9 買収による技術優位性の獲得 234
3.9.1 3dfx Interactive の買収 (2000) 234
3.9.2 MediaQ の買収と Tegra シリーズ (2003) 235
3.10 戦略的パートナーシップ 237
3.10.1 Sony Playstation 3 (2000 年代 ) 237
3.10.2 Microsoft Xbox 360 (2000 年代 ) 238
3.10.3 IBM HPC 高性能コンピューティング (2000 年代 ) 238
3.10.4 Audi Google Earth ナビゲーション (2000 年代 ) 238
3.10.5 NVIDIAが日立にSH7786評価ボードを20枚注文 240
3.10.6 Tesla Motors (2000 年代 ) 243
3.11 AI 革命の黒子として地道にビジネスを拡大 243
3.11.1 AI ディープラーニングの到来 243
3.11.2 NVIDIA GPU が AI の研究開発に不可欠なものに 245
3.11.3 NVIDIA GPU と CUDA は AI 開発を民主化 246
3.11.4 業界へのインパクト 247
3.12 CUDA プラットフォーム 247
3.12.1 CUDAによる大規模並列計算の普及 248
3.12.2 CUDAの並列計算モデル 249
3.12.3 処理の順序やデータ依存性のサポート 249
3.12.4 CUDAにおける並列処理のしくみ 249
3.12.5 メモリ階層とデータ転送 250
3.12.6 CUDAライブラリ(並列演算ソフトスタック)): 251
3.12.7 CUDAによるコンピュータサイエンスへの貢献 252
3.12.8 CUDAはAI研究者に翼を与えた 253
3.12.9 CUDAは産業を変革:ゲノミクスからロボティクス 254
3.13 CUDA のはしり : グラフィックス用 C 言語 Cg 254
3.13.1 プログラマブルシェーダーとは 255
3.13.2 プログラマブルシェーダーの歴史 255
3.13.3 NVIDIA による独自シェーダーコンパイラ開発 256
3.13.4 市場の NVIDIA シェーダーコンパイラ Cg への反応 257
3.13.5「CUDA」の語源 259
3.13.6 Cg から「CUDA」への量子的飛躍(Quantum Leap ) 260
3.13.7 GPU 開発ツール「CUDA Toolkit」 261
3.13.8 CUDA デバッグツール NVIDIA Nsight 262
3.13.9 GPU ドキュメントとサポート 262
3.14 チップ会社ではソフトは「損失するだけの役務」? 263
3.14.1 初期のジェンセンはソフトをこう考えた 263
3.14.2 ジェンセンの「SHフランチャイズ」批評 264
3.14.3「NV1」から NVIDIA が当時学んだこと 265
3.14.4 Cg コンパイラ開発人員拡大に当初反対 (2003 年 ) 266
3.14.5 IPO 後のエンジニアの心境 (2003 年 ) 267
3.14.6 Linus と Stallman とオープンソース 267
3.14.7 NVIDIA から WIndows OS 開発者を引き抜く 269
3.14.8 NVIDIA からきた優秀な技術者たち 270
3.14.9 孤軍奮闘の Cg コンパイラ若手技術者 (2002) 271
3.14.10 汎用 GPU と呼ばれるための条件 273
3.14.11 GPU プログラムの容易性を CUDA でアピール 273
3.14.12 参考文献 274
3.15 研究者を根こそぎ NVIDIA 推進に動員 274
3.15.1 Google TensorFlow を NVIDIA に最適化 274
3.15.2 Google Cloud を統合 275
3.15.3 Amazon Web Services (AWS) から GPU サービス提供 275
3.15.4 Amazon マシン イメージ(AMI)で AI 研究加速 275
3.15.5 Microsoft: Azure Machine Learning を統合 275
3.15.6 大学との AI 研究協力 276
3.16 NVIDIA の最先端 AI チップアーキテクチャ 277
3.16.1 NVIDIA GPU アーキテクチャの方向性 277
3.16.2 NVIDIA GPU アーキテクチャの歴史 278
3.16.3 GPU アーキテクチャと CUDA を連携 279
3.17 テンソルコア(Tensor Core) 280
3.17.1 行列演算の高速化 281
3.17.2 マトリックス積の実装(Fused Multiply-Add, FMA) 282
3.17.3 複数精度演算のサポート 282
3.17.4 トランスフォーマーエンジンとの連携 283
3.17.5 テンソルコアが活躍する応用分野 283
3.18 ホッパー(Hopper)アーキテクチャ 284
3.18.1 ホッパーアーキテクチャの特徴 284
3.19 トランスフォーマーエンジン 285
3.19.1 トランスフォーマー アーキテクチャの背景 285
3.19.2 トランスフォーマーエンジンの詳細 285
3.19.3 トランスフォーマーエンジンの応用 286
3.20 動的計画法(DP = Dynamic Programming) 287
3.21 MIG(Multi-Instance GPU)で複数タスク同時実行 287
3.22 NVLink 4.0 は GPU-GPU-CPU 間転送を高速化 288
3.23 HBM3 メモリ(High Bandwidth Memory 3) 288
3.24 NVIDIA に挑む AI チップ群 290
3.24.1「AI の戦国時代が 2025 年から始まる」 290
3.24.2 大手 IT 企業が独自 AI チップで参戦 291
3.24.3 AMD は RDNA と ROCm で CUDA を追撃 291
3.24.4 Intel は Ponte Vecchio, Gaudi, Mobileye 買収で対抗 295
3.24.5 Google は TPU でクラウド AI で NV 置き換え 300
3.24.6 Tesla は自動運転 AI チップ Full Self-Driving を内製 300
3.24.7 Amazon は AI チップ Trainium と Inferencia を内製 301
3.24.8 Qualcomm はモバイルと車載応用 AI チップで挑戦 301
3.24.9 Apple は M シリーズ内蔵 GPU で NVIDIA に挑む 302
3.24.10 Tenstorrent の「Grayskull」と「Wormhole」 302
3.24.11 Graphcore の Intelligence Processing Unit 303
3.24.12 Cerebras Systems の Wafer Scale Engine 303
3.24.13 SambaNova の Reconfigurable Dataflow Unit 304
3.24.14 Mythic AI のアナログ AI 推論チップ 305
3.24.15 Groc の Tensor Streaming Processor 305
3.24.16 NVIDIA へ挑戦する企業のまとめ 306
3.25 NVIDIA のイノベーションで産業界の変革が開始 307
3.25.1 ヘルスケアとライフサイエンス業界 307
3.25.2 自律走行車と輸送業界 308
3.25.3 製造とロボット業界 309
3.25.4 金融と銀行業界 309
3.25.5 金融リスク管理とコンプライアンス応用 310
3.25.6 メディアとエンターテインメント業界 310
3.26 参考文献 311
3.27 終わりに 311
3.28 独りごと 311
4. Arm の新戦略:TSMC 最適化 IP で性能・効率・面積 を改善 315
4.1 Arm 売上額と出荷個数の推移 315
4.2 Flexible Access の拡がり 315
4.3 組み込み向け Arm アーキテクチャーと IP の進展 317
4.4 組み込み向けチップ製品例 320
4.5 コンピュートサブシステムは特定ファウンドリ向け 320
4.6 参考文献 321
5. TSMC の 24 年間:売上推移と技術ノードの変遷 323
5.1 TSMC 売上額の推移 323
5.2 利益額と利益率 326
5.3 参考文献 327
6. DARPA 自動設計フローで Google 助成シャトルで RISC-V 試作 329
6.1 1MB+ のメモリを持つ MARMOT RISC-V を実現 330
6.2 Google 無償シャトルで幸運が訪れる 331
6.3 Efabless 社キャラベルハーネス(Caravel Harness) 332
6.4 Linux 型 IoT エッジと RTOS 型 IoT エッジ 333
6.5 オープンロード作業ログ(2022 年) 333
6.6 Efabless 社が試作したチップをソフトで検証(2024) 335
6.7 MPW-6 デモ (2024 年 8 月 1 日、11 月 20 日 ) 338
6.8 会員配布用『JASA1 チップ評価ボード』(企画段階) 339
6.8.1 『JASA1 チップ評価ボード』のコストイメージ 340
6.8.2 QPI フラッシュでの Dual, Quad 接続の初期化(済) 341
6.8.3 QPI フラッシュ直接実行性能の実機評価(進行中) 342
6.8.4 Chisel ソースコードの公開(進行中) 342
6.8.5 QPI フラッシュからキャッシュを介し直接実行 344
6.8.6 MPW-7 Marmot では 50MHz の高速動作が可能 344
6.8.7 Chisel 検証は論理シミュレーションと FPGA で 344
6.8.8 MPW-7 Marmot の PSRAM 直接実行機能を JASA1 に 345
6.9 Chisel 勉強会 346
6.9.1 『Chisel で始めるデジタル回路設計』 346
6.9.2 Arty A7 FPGA 上で Chisel の動作検証 347
6.10 これからの計画 347
6.11 MPW-8 は自主開発の SH-2 を公開 348
6.12 感想 349
6.13 結論 349
6.14 謝辞 349
7. RISC-V と共に成長するアンデス:台湾 No.1 IP 企業の 未来 351
7.1 RISC-V の 30% シェアを持つアンデス テクノロジー 351
7.2 CPU IP ラインアップと 2030 年に向けた戦略 354
7.3 2030 年に向けたビジョン 361
7.4 参考文献 363
8. テンストレントが提供する DX のためのスケーラブル な RISC-V 365
9. シンプルなマイクロコントローラ から複雑なマル チコア SoC まで
ー RISC-V ベースのチップのデバッグが簡単に 391
10. RISC-Vと米中対立:分断を超えて続くオープンソー ス協力 401
10.1 はじめに 401
10.2 RISC-V の起源と基本的な特徴 401
10.2.1 命令セットアーキテクチャ、ISAとは 402
10.2.2 「命令セット」を支配する企業が受ける戦略的特 404
10.2.3 RISC-Vが出現した理由 404
10.2.4 GoogleがでRISC-Vを大規模支援するわけ 405
10.2.5 加州大バークレー校「RISC命令セット」40年史 406
10.2.6 RISC-VのビジネスモデルのArmとの相違 408
10.2.7 IP収入、設計着手件数でArmを凌駕(2023) 409
10.2.8 IPOで資金調達ではArmがRISC-Vをリード 410
10.2.9 ArmはAppleライセンス料値上げ要求を撤回 411
10.2.10 先端 RISC-V と先端 Arm の性能比較 412
10.2.11 Google と Qualcomm がタッグを組み RISC-V 用 アン
ドロイドを完成 中国もこれを活用 413
10.2.12 Bosch、Qualcomm、Infineon の車載 RISC-V IP 415
10.3 中国で 300 社以上が RISC-V を使用し製品開発 416
10.3.1 T-Head(Pingtouge)RISC-V「Xuantie」(玄鉄) 417
10.3.2 アリババ「Xuantie」(玄鉄)RISC-V システム 418
10.3.3 HiSilicon 社 RISC-V「Hi3861」 418
10.3.4 ファーウェイ Hi3861 RISC-V エコシステム 419
10.3.5 StarFive の RISC-V JH7110 SoC 421
10.3.6 中国 Terapines はソフトハード共同設計環境を提供 422
10.3.7 中国科学院「XiangShan」(香山)オープン RISC-V 423
10.4 中国へのスーパーチップ禁輸措置と RISC-V 424
10.4.1 米国の中国へのデジタル半導体技術の輸出規制 424
10.4.2 日本政府の輸出規制への対応 424
10.4.3 2023 年度欧州 RISC-V サミットで中国と台湾が対話 426
10.4.4 米国議員がバイデン政権へ RISC-V 輸出規制を要求 426
10.4.5 オープン工業規格の輸出規制は難しい 427
10.4.6 RISC-V に輸出規制がかかる可能性は否定できず 428
10.5 日本の RISC-V に関する半導体政策 429
10.5.1 経済産業省主導の RISC-V 助成事業 2018-2023 429
10.5.2 APEC2023 での日米経済安全保障と技術協力の確認 429
10.5.3 APEC 2023 直後の小型原子炉(SMR)日米協力発表 430
10.6 日本政府の統合政策としてのラピダス創生 431
10.6.1 外交政策、安全保障政策、経済政策を統合 432
10.6.2 ラピダスとテンストレントの戦略提携 433
10.6.3 ラピダスに寄せられる日米両政府の期待 434
10.6.4 民生・軍事デュアルユース製造技術開発 435
10.6.5 NVIDIA は軍事民生デュアルユース AI チップを製造 436
10.6.6 ラピダスと RISC-V CPU と AI チップ企業群が提携 437
10.6.7 ラピダスと Arm ユーザ半導体メーカの提携 438
10.7 RISC-V が半導体業界に残す足跡 439
10.7.1 オープンソース哲学をハードウェア設計へ適用 439
10.7.2 生成AIにおけるオープンアーキテクチャの重要性 440
10.7.3 電子技術の進化が要求する半導体人材の質的変化 440
10.7.4 ハードウェア設計の民主化 441
10.7.5 RISE: 新アーキテクチャのソフトサポート戦略 442
10.7.6 RISC-V技術でも米中間の覇権争い 442
10.7.7 ビッグアンブレラ哲学によるグローバル協力 443
10.7.8 参考文献 446
• 編著者紹介 448
• あとがき 451
